Compressing X.509 certificates
Introduction
I run a Certificate Transparency monitor which retains a copy of all the certificates it downloads. As CT logs are append-only, the monitor’s disk usage keeps creeping upwards. I’m always on the look out for ways to optimize disk usage to delay the need to buy bigger disks!
De-duplication
A few months ago I saved lots of space by de-duplicating the certificates. The
original version of the monitor stored the raw leaf_input and extra_data
fields of each entry. However, leaf certificates often end up in at least three
logs and there are a relatively small number of intermediate and root
certificates repeated over and over again. The leaf_input can’t be
de-duplicated directly as it varies between logs even for the same certificate
(e.g. the entry timestamps are almost always different), therefore, the new
version of the monitor decodes the leaf_input and extra_data fields and
stores the decoded data, allowing just the certificates to be de-duplicated.
This reduced the disk usage from around 500 GiB to 150 GiB.
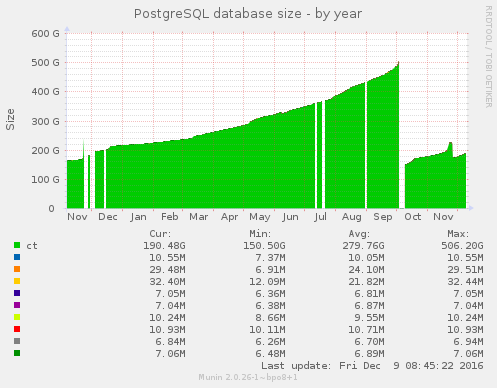
Since then the disk usage increased to 195 GiB, so I decided to look at whether compression would make a significant saving.
Packed Encoding Rules
The certificates are currently stored in DER format. ASN.1 also defines a more compact mechanism for storing data than DER: Packed Encoding Rules (PER). However, PER isn’t suitable for this use case:
-
PER requires that the schema is known in advance. However, X.509 certificates support arbitrary extensions so it’s impossible to come up with a schema that will accept all possible extensions.
-
It’s likely that some certificate authorities have issued certificates that are not encoded correctly in DER, so it might not be possible to convert them to PER or get back to the original DER. Reproducing the exact encoding used by the log is required to calculate the log’s current Merkle tree hash.
Postgres TOAST compression
I decided that compressing the DER itself would be the best approach. The
certificates are currently stored in a BYTEA field in a Postgres database, and
it turns out that Postgres already compresses large rows itself. It has a
maximum row size of 8,192 bytes. When a row grows larger than 2,048 bytes,
Postgres uses a technique known as TOAST to try to fit the row into
8,192 bytes. First, it compresses the row with a custom variant of LZ77.
If it’s still too large, it stores the data out-of-line, with the row
containing pointers to the out-of-line data.
However, in a sample of 100,000 certificates selected randomly from the CT logs, only 3,179 (≈ 3%) were larger than 2,048 bytes, so Postgres’s built-in compression was only applied to a minority of certificates. Although the 2,048 byte threshold can be tweaked, I decided to do the compression at the application level.
Compressed X.509 Format
While deciding which compression algorithm to use, I found an interesting draft RFC from 2010, draft-pritikin-comp-x509-00. It defines the Compressed X.509 Format (CXF), which, as the name suggests, is designed specifically for compressing certificates. It’s essentially DEFLATE with a custom preset dictionary.
Preset dictionaries save space if you’re independently compressing lots of small items (such as certificates) as you don’t need to include the dictionary with the compressed data over and over again. The dictionary be distributed out-of-band a single time instead – for example, by embedding the it in the compression program itself.
Here’s a simple CXF implementation I wrote in Java:
private static final byte[] CXF_DICTIONARY = Base64.getDecoder().decode(
"MIIBOTCCASOgAwIBAgIBATANBgkqhkiG9w0BAQUFADAZMRcwFQYDVQQDEw5odHRw" +
"Oi8vd3d3LmNvbTAeFw0xMDA1MTExOTEzMDNaFw0xMTA1MTExOTEzMDNaMF8xEDAO" +
"BgkqhkiG9w0BCQEWAUAxCjAIBgNVBAMTASAxCzAJBgNVBAYTAlVTMQswCQYDVQQI" +
"EwJXSTELMAkGA1UEChMCb24xDDAKBgNVBAsTA291bjEKMAgGA1UEBRMBIDAfMA0G" +
"CSqGSIb3DQEBAQUAAw4AMAsCBG6G5ZUCAwEAAaNNMEswCQYDVR0TBAIwADAdBgNV" +
"HQ4EFgQUHSkK6busCxxK6PKpBlL9q8K1mcQwHwYDVR0jBBgwFoAUn7r/DVMuEpK9" +
"Rxq3nyiLml10+nQwDQYJKoZIhvcNAQEFBQADAQA="
);
public byte[] compress(byte[] in) throws IOException {
Deflater deflater = new Deflater(Deflater.BEST_COMPRESSION, true);
try {
deflater.setDictionary(CXF_DICTIONARY);
deflater.setInput(in);
deflater.finish();
try (ByteArrayOutputStream out = new ByteArrayOutputStream()) {
byte[] buf = new byte[4096];
while (!deflater.finished()) {
int len = deflater.deflate(buf, 0, buf.length);
out.write(buf, 0, len);
}
return out.toByteArray();
}
} finally {
deflater.end();
}
}
Decompression is very similar and left as an exercise for the reader for brevity.
CXF’s preset dictionary is a valid X.509 certificate containing several common subject/issuer fields and extensions. Some of the fields are left blank (e.g. subject CN), some contain a dummy value (e.g. subject/authority key identifier and the RSA modulus) and some contain the most likely value (e.g. subject country code of “US”, X.509 version number of 3).
Here’s the openssl x509 -text output:
$ <<EOF base64 -di | openssl x509 -inform der -text -noout
> MIIBOTCCASOgAwIBAgIBATANBgkqhkiG9w0BAQUFADAZMRcwFQYDVQQDEw5odHRw
> Oi8vd3d3LmNvbTAeFw0xMDA1MTExOTEzMDNaFw0xMTA1MTExOTEzMDNaMF8xEDAO
> BgkqhkiG9w0BCQEWAUAxCjAIBgNVBAMTASAxCzAJBgNVBAYTAlVTMQswCQYDVQQI
> EwJXSTELMAkGA1UEChMCb24xDDAKBgNVBAsTA291bjEKMAgGA1UEBRMBIDAfMA0G
> CSqGSIb3DQEBAQUAAw4AMAsCBG6G5ZUCAwEAAaNNMEswCQYDVR0TBAIwADAdBgNV
> HQ4EFgQUHSkK6busCxxK6PKpBlL9q8K1mcQwHwYDVR0jBBgwFoAUn7r/DVMuEpK9
> Rxq3nyiLml10+nQwDQYJKoZIhvcNAQEFBQADAQA=
> EOF
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 1 (0x1)
Signature Algorithm: sha1WithRSAEncryption
Issuer: CN=http://www.com
Validity
Not Before: May 11 19:13:03 2010 GMT
Not After : May 11 19:13:03 2011 GMT
Subject: emailAddress=@, CN= , C=US, ST=WI, O=on, OU=oun/serialNumber=
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (31 bit)
Modulus: 1854334357 (0x6e86e595)
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
X509v3 Subject Key Identifier:
1D:29:0A:E9:BB:AC:0B:1C:4A:E8:F2:A9:06:52:FD:AB:C2:B5:99:C4
X509v3 Authority Key Identifier:
keyid:9F:BA:FF:0D:53:2E:12:92:BD:47:1A:B7:9F:28:8B:9A:5D:74:FA:74
Signature Algorithm: sha1WithRSAEncryption
$
Constructing a DEFLATE dictionary
I wondered if I could do a better job of constructing a dictionary. There’s no reason that the dictionary has to be a valid X.509 certificate, other than ease of constructing/distributing it. Constructing a dictionary that isn’t constrained by the X.509 certificate structure could lead to several improvements. Some of my initial ideas included:
-
Adding OIDs for more signature algorithms, such as SHA-256 with RSA and ECDSA.
-
Adding more common values for the various fields – e.g. more country codes than “US”, more TLDs than “.com”, etc.
-
Omitting the random values for the RSA modulus and subject/authority key identifiers, as they’re unlikely to be useful.
-
Including a larger number of common X.509 extensions, such as:
- Key Usage
- Extended Key Usage
- Certificate Policies
- Subject Alternative Name
Last year CloudFlare wrote a blog post on using preset DEFLATE dictionaries, though from the perspective of compressing HTML pages rather than certificates. Together with the post they released an open-source tool for automatically constructing DEFLATE dictionaries from a sample of training data: dictator.
dictator runs “pseudo” LZ77 against the sample data to find strings that
DEFLATE wouldn’t be able to compress. It calculates a score for each string
based on popularity and length. The highest scoring strings are used to create
the dictionary.
This saved me the need to construct a dictionary by hand, which might not have
ended up being very effective. I just took a sample of 100,000 certificates from
the CT logs and used dictator to generate one automatically.
I’ve uploaded the dictionary it generated (encoded in Base64) in case anyone else finds it useful.
Running strings against it is quite interesting – it includes common terms
like “Domain Validated” and “DV”, names of some popular CAs, common OCSP/CRL
URLs and even the disclaimer included in the certificatePolicies extension in
every Let’s Encrypt certificate.
I expect examining it with xxd will also show it contains some common OIDs and
other bits of DER encoding, but I didn’t look myself to avoid spending effort
decoding DER by hand!
Results
As I was slightly concerned about overfitting, I decided to test how well the
dictator-generated dictionary worked in comparison to plain DEFLATE and CXF
with a completely different sample of 100,000 certificates. I used a compression
level of 9 in all cases.
Here are the results:
| Algorithm | Mean certificate size (bytes) |
|---|---|
| Uncompressed | 1433.67 |
| DEFLATE | 1144.19 |
| DEFLATE with CXF dictionary | 1080.59 |
DEFLATE with dictator-generated dictionary |
930.33 |
Shaving off over a third of the bytes on average is pretty impressive, especially considering that some data in a certificate (e.g. the public key and signature) is random and therefore impossible to compress.
Postgres bloat
I decided to go ahead and compress all the certificates in my CT monitor’s
database with the dictator-generated dictionary. Although saving 500 bytes per
certificate may not sound like much, at the time of writing there are around 69
million certificates in the database (and it keeps growing!)
Just before I started the compression process, the database’s disk usage was approximately 195 GiB. Around 70 GiB was used by the certificates themselves. Indexes and other tables made up the remaining disk usage.
As compressing all the certificates was a one-off job I didn’t spend lots of time optimizing the code, so it took around 4 days to run.
Postgres uses multiversion concurrency control (MVCC) to implement transaction
isolation, which means UPDATEs are internally implemented as a DELETE
followed by an INSERT. Deleted rows stick around in case another transaction
is still reading the row.
The VACUUM command marks deleted rows that are no longer visible to any
transactions as free, allowing the space occupied by the row to be re-used. If
the deleted row is at the end of the data file the free space can be returned to
the operating system.
As it took a while for the automatic vacuuming process to kick in, the size of the table initially grew during the compression process:
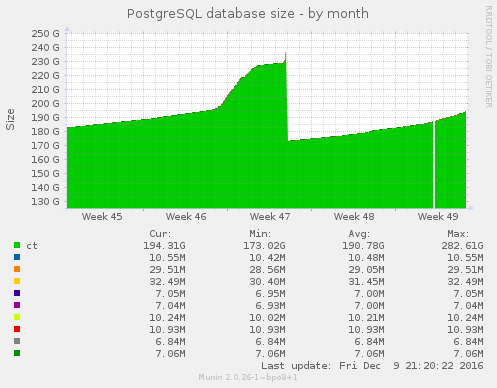
The growth slowed down after the autovacuum kicked in as compressed certificates could be inserted in gaps left by the vacuumed rows. However, the new rows didn’t fit perfectly in all the gaps so some free space, known as bloat, was still left over.
VACUUM FULL can be used to eliminate bloat. It makes a copy of the entire
table, packing the rows together tightly with no free space between them. The
old table is then deleted. This is visible in the graph as a brief spike (as
both the old and new table exist simultaneously) before the steep drop to
approximately 173 GiB (from 195 GiB at the start of the process).
As the monitor was still running over the 4 day compression period, the before and after sizes can’t be compared directly. Excluding the additional certificates downloaded during those 4 days, the size of the certificates table dropped from around 70 GiB to 45 GiB – a saving of 25 GiB.
Conclusion
The 25 GiB saving wasn’t quite as good as I expected – I over-estimated how much disk space was used by the certificates table in comparison to the rest of the database. However, it’s still a reasonable amount – it saved enough room for another month or so of growth, and the rate of growth is slower now too.
There are opportunities for further work in this area – for example, comparing DEFLATE against other compression algorithms.
It doesn’t just apply to CT monitors either. QUIC, a mix of HTTP/2, TLS and TCP implemented directly on top of UDP, already implements certificate chain compression to reduce round trip times. It uses gzip and a preset dictionary, which is constructed dynamically by concatenating:
-
~1500 bytes of common substrings from certificates taken from the Alexa top 5000 list.
-
Certificates the client already knows about (e.g. intermediate certificates or certificates from a previous interaction with the same server).
Purely by coincidence, there was a discussion on the TLS working group mailing list recently about adding a QUIC-style certificate compression extension to TLS.